The Cognitive Flood
What a developer faces when entering the AI-assisted development world
I coding tools are extraordinarily powerful and getting better all the time. Developer-oriented solutions like Claude Code, GitHub Copilot, Cursor, Windsurf, Antigravity have slightly different approaches but seem to rapidly reach feature parity. Similarly, more product-oriented services, such as Lovable, seem to produce more and more finished solutions with just a single prompt, and gain more and more features every month.
They all suffer, regardless of the latest context engineering feature or a UX trick, from similar issues when applied without proper guidance and expertise. Examples of these symptoms, but not limited to, are wandering agents, rotten contexts, and results that can't be traced back to the requirement. Or, total misses like the product contains pretty much everything else but the thing you really wanted, and even those often barely working.
Worse yet, the larger the codebase gets the worse the results get. Throwing more tokens, iterations or subagents may help sometimes but they are essentially brute-force techniques which are not only expensive but very ineffective.
Let's take a moment to look at what happened to my game in the beginning.
When starting my roguelike project, I was very well on board with the domain. I picked Get-Shit-Done (GSD) as my project manager, planning assistant, and agentic coordinator as I felt it is surely enough for a single-developer problem. So it was, nicely integrated with Opencode, a real quickstart and easy to interact with. The biggest issue was perhaps to understand the assumed project structure of milestones, roadmap, and phases, each of which have the same lifespan.
(Btw I've grown much more fond of Opencode than Claude Code).All these new techniques and tools are powerful, but add to something I call concept overload. Some might refer to it as the "cognitive load", but we're talking about essentially the same thing and I've probably used these terms interchangeably in this book already. Think about if your workplace introduced new processes, new paradigms, new strategies, new tools so frequently that it's impossible to keep up. That's the situation for many right now.
The issue isn't just a cognitive problem, but an emotional one. Concept overload is causing anxiety for people whose careers were built on skills that are now being automated. The developer who spent a decade mastering a framework watches an AI generate equivalent code in seconds. The architect who prided themselves on system design sees AI proposing (better) alternatives (I'd be the first to admit it). The uncertainty isn't abstract; it's personal, and it colors every interaction with the new tooling.
Introduction to new concepts
Consider the following image: how many totally new concepts are there for an average developer to learn when they start AI-assisted development? A lot. And this is just the beginning: not only do you need to master these terms, you also need to become 'AI-literate' and learn how to avoid getting 'AI-lazy'.
Let's split the concepts used in the diagram above into six categories. (The diagram btw, as all the others was indeed generated by my trustful AI companion as SVG/JSX in case you're interested. None of them were, regrettably, exactly one-shotted)
- Processes
- Methods like prompt engineering, spec-driven development, vibe coding, software factory patterns are all ways to organize work and interact with the AI.
- Agents
- Non-determinism, orchestration, swarms and parallelism, function and tool calls, skills (to name a few) are the mechanics of how AI agents actually operate.
- Models
- Classes and sizes, providers, token usage, mixture of experts, chain of thought, thinking modes, system prompts, custom instructions are vague terms related to LLM models and their usage. Might not be needed to be understood in depth, but add to the confusion when they are.
- Developer Tools
- IDEs, CLIs, MCPs, skills, extensions and plugins are the interfaces through which developers interact with AI. Each with different capabilities and different assumptions about workflow. The pace of development is crazy, and even for a seasoned specialist often intolerable.
- Context
- Size limits, engineering, rot, compacting, transparency issues are the single biggest quality determinant in AI-assisted development. Unfortunately it's hard to understand and the tools are pretty bad at visualizing it. The importance of context engineering and developing necessary developer 'context awareness' is a thing that needs to be understood and mastered to get good results.
- Documentation
- Custom instructions, agent definitions, skills, architecture decision records, UX specifications, stack descriptions, task management artifacts constitute the written layer which determines whether the code aligns with your project's reality or drifts into generic patterns.
The role disruption
In addition to learning a lot of new concepts, we might need to rethink our roles in our field.
I've summarized my thoughts and visions on how the established roles and well understood job descriptions might change (or 'get realigned' in corporate) in this new world, and what new skills and focus areas they might need to develop along the way in the table below.
| Role | Traditional Focus | Now Facing | Impact |
|---|---|---|---|
| Product Owner | Requirements clarity, prioritization | How specific must specs be if AI writes code? Can AI help refine requirements? | Must learn to write specification-like requirements |
| Architect | System design, technology choices | Can AI design systems? How do you architect for AI generation? | Must understand code generation patterns and searchability |
| Designer | UX/UI design, user workflows | Do UI designs become prompts for AI? How detailed must they be? | Must understand constraint communication |
| Team Lead | Velocity, scope, team cohesion | Uneven expertise across AI-capable tools | Must actively manage skill gaps and tool adoption |
| Developer | Implementation, problem-solving | When does AI replace judgment? What's left to learn? | Must develop new skills: spec verification, prompt design, governance |
| Tester | QA, regression, edge cases | Can AI find its own bugs? What does testing look like at scale? | Must understand AI-generation failure modes |
| SRE/DevOps | Infrastructure, deployment, reliability | How do you monitor AI-generated code in production? | Must develop observability for probabilistic systems |
So if anything above is actually valid, we'll shift from producing to governing, from doing to validating. We'll explore what this means for each role in depth in Chapter 6, but the pattern is already visible: every role needs to develop a new relationship with verification, specification, and trust. I'll admit: most of this is still speculation. Nobody has properly battle-tested it, at least in the long term.
Let's not throw the good things about Agile away when jumping on Agentic Spec Driven Development bandwagon. Let's at least keep the Self Governing Teams and Continuous Feedback Loops, and this time (let team really) live by them.
People are smart and given trust and responsibility, they will figure out how to make it work.
Later we'll also discover that the new set of tools and processes might give us entirely new roles to fill.
The team challenge: How to work together with AI
Essentially, developers and teams face the same question: how do you let AI agents 'do the work' while maintaining the accountability, traceability, and quality that professional delivery demands?
All of the above is hard enough even without AI, even when you have clear roles, a mature toolset, and processes. Be prepared that in the current wave you will get neither of these off the shelf.
Team leads, lead devs, project managers et al need to figure out:
- How do you plan, structure and organize teamwork now that the coding part is increasingly automatic, tools are immature and constantly changing?
- What kind of new roles, feedback loops and processes do I need to fill, onboard, develop, execute and keep track of?
- How to get the most out of this technology and remain sane, on budget and on schedule?
This book aims to give you some answers on these concerns.
Planning and coordinating work
There are several approaches to organize software development into manageable chunks. They range from very lightweight and flexible (vibe coding) to very structured and rigid (waterfall).
Each has different implications for how AI can be integrated and governed.
Some approaches strive to produce useful results early on, some only target go-live later in the process. The most lightweight is no plan at all: prototyping. It has been recently renamed to "vibe coding."
Here's a summary of the approaches and their implications for AI-assisted development (and perhaps in any software development context):
| Approach | Chunk Size | Outcome Delivery | Validation Timing | AI Suitability |
|---|---|---|---|---|
| Vibe Coding | Arbitrary; follows intuition | Continuous experimentation | After the fact | Excellent for exploration; poor for production |
| Iterative/Agile | Small stories/tasks | Early and frequent releases | Each iteration | Good with proper specs and tests |
| Phase-Gated | Medium features/milestones | Per phase completion | End of each phase | Requires thorough phase specifications |
| Waterfall/Big-Bang | Large; entire system | Single go-live | End of project | Poor; late feedback |
The choice of approach (which typically has properties from several of the categories above) dramatically affects how AI assistance can be governed.
Vibe coding maximizes AI's creative potential but sacrifices traceability. A waterfallish approach demands specifications AI can follow but provides feedback quite late. Iterative approaches often offer the best balance: structured enough for governance, flexible enough for AI's strengths.
Recent critiques of AI-powered software engineering, and even SDD, miss the point though. Doing proper planning up front does not mean that the entire process needs to be the old 3-year waterfall. Even vibe coding, as implausible as it might sometimes still be, can be a useful tool for instance to prototype a new user experience feature.
Context engineering to the rescue?
Now on to the next big word in AI-powered software development: context engineering.
What it really is: when you call an LLM to work for you, you pass in a long text called a prompt. Perhaps you attach some files, and the AI does some lookups, and responds. That's the Context. Think of it like a transcript of your chat.
As the name suggests, context engineering is the collection of techniques related to what gets in that context. As in discussions, you should be very careful what to say to keep it on track and on subject, and include the relevant details for the other party to do its job, decision, or whatever.
All this is kind of quite complicated with AI.
When we strip the agentic software factory into bare essentials, it's worthwhile to note that essentially we're still crafting prompts and getting some response. All an 'agent' is is a multi-step prompt parsing, with some added capabilities via tools. The fundamental model is deceptively simple:
input → f(x) → output
The input is the context: your prompt, system instructions, conversation history, tool results, file contents, i.e. everything the model sees. The f(x) is the transformer: a statistical function that predicts the most likely continuation. The output is the generated response. Even though the LLMs don't have a concept of session, but everything is a 'post back' as in the old days of web development, the context is essentially the session state. Kind of 'transient component' if you will.
The quality of your output is bounded by the quality of your input. No amount of model capability compensates for a poorly constructed context.
And here's where it gets worse.
Despite improvements in context window sizes, up from 4K tokens in early GPT models to 200K+ in current ones, limits still exist, and bigger isn't always better. Context can be rotten: filled with conflicting instructions, outdated information, irrelevant code, or redundant history. As the context grows, the model's ability to attend to the right information degrades. Quality decays not because the model got dumber, but because the signal-to-noise ratio in its input dropped.
Context engineering, then, is the discipline of crafting, curating, and maintaining the information that feeds AI systems. It spans all dimensions of software development from requirements to architecture to code to tests. Arguably, it's actually the reason behind most of the tips, techniques, and practices I'm discussing in this book.
You could think of context engineering as kind of a continuum from prompt engineering), but this time it's the agents/LLMs doing the prompting, not you. Put simply, it's about ensuring AI has the right information at the right time, and nothing more.
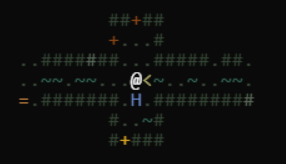
I've illustrated the challenge with contextin my Developer Feeling Meter (tm) below. I'm pretty sure it's rather familiar for those who've worked with LLMs for a while.
Be smart and stay in the smart zone. Say /clear or press that + for a new session when the things start to get worse. Don't try to force it through with more tokens or more iterations. It's not going to work.
Too many tools, not enough time
According to the JetBrains 2025 Developer Ecosystem Survey, 85% of developers now use AI-assisted tools. But which tools and to what extent? There is a strong lineup of tools for you to pick: GitHub Copilot, Cursor, Windsurf, Claude Code, Antigravity, Codex CLI, Opencode, each with slightly different strengths, context management approaches, pricing models, and feature sets.
Another very recent study conducted by the Practical Engineer blog discovered that 95% of respondents used AI tools for software development at least weekly. https://open.substack.com/pub/pragmaticengineer/p/ai-tooling-2026?utm_campaign=post&utm_medium=email
But regardless of which specific tools you pick, the underlying architecture is converging. In Chapter 18, we'll map how users, models, prompts, agents, instructions, files, tools, skills, and integration protocols like MCP (Model Context Protocol) and LSP (Language Server Protocol) fit together as a layered system.
As always, you need some practice around choice of tools: how to assess new tools without disrupting ongoing work, how to standardize without stifling individual productivity (remember emacs vs vi), how to share learnings across the organization.
This pace and volume of new development gadgets isn't a reason to avoid AI. I think but it's a reason to invest in the governance layer around them, which is exactly what this book proposes, and judging by the fierce competition to reach feature parity, remaining as Agent Harness agnostic as possible might be a good idea to wait until the smoke clears and the victors emerge.
I am aware that the odds are that many things I assert in this book are going to be outdated in a year or two. Yes, it's possible that we have that Automated Agentic Software Factory doing all and anything we used to do for a living this just around the corner. You know, coming out of the beta right next quarter.
Why this matters
There are two big risks that I see resulting from ingesting too much new, often confusing and not that well defined, vague concepts in a short time.
Taking the easy path. When overwhelmed by the volume of new concepts and tools, teams default to the path of least resistance: let AI generate code, skip the review ("it looks fine"), merge it, move on. The result is a codebase that nobody truly understands, with subtle bugs that surface weeks later and architectural drift that compounds over time.
Dismissing the whole thing. After a bad first experience like a hallucinated API, a generated test that tests nothing, an agent that rewrote the wrong file, teams conclude that AI coding tools "aren't ready" and go back to doing everything manually. They miss this impressive possibility to up their game because the first impression was poor and there was no framework for understanding why.
Both of these responses are understandable.
In the rest of this book, I'll introduce some tools and observations to help you and your team navigate between these extremes.